This is a text-based summary from the IROS 2020 Perception, Learning, and Control for Autonomous Agile Vehicles Workshop. The following post aims to summarize the key takeaways as well as explain some technical terms/concepts not elucidated in the tutorials. Some frequently asked questions will be included in the content and answered in a different document to not ruin the flow of the tutorial.
Speaker:
Nikolai Smolyanskiy, NVIDIA
Agenda:
- Autonomous Vehicles Stack and Deep Learning
- Overview of Multi-view Perception DNNs
- Overview of Prediction and Planning DNNs
- An argument for Modular Deep Learning-Based AV Pipelines
- FAQs
Overview Of Current Navigation Stack
- What does a typical navigation stack we find in autonomous systems today look like? And how much deep learning goes on in each of these components? Here’s a quick breakdown:
- Localization and Mapping (0 % DL)
- Perception (90% DL)
- Prediction (50% DL)
- Planning (0 % DL)
- Control (0 % DL)
- Due to safety and complexity, it is hard to apply end-to-end DL in all components of the pipeline. Only the perception and planning are learnable components, while the other are all hand-engineered by humans.
- As a result, due to a lot of hand-engineering going on, the current system is typically complex, and very brittle – meaning a navigation stack developed for one system cannot easily be transferred to another with ease.
- Nikolai however argues that Deep Neural Networks (DNNs) can be made completely end-to-end. He argues that each module listed above can be made completely DL-based and the output of each module can be made in some human-understandable form so that we can verify it adding a layer of safety to the system.
Perception Deep Neural Networks for LIDARs and Cameras
- Multi-view LIDARNET (MVLidarNet) DNN
- This section of the talk summarized the key insights from Multi-view LIDARNET, which was presented at IROS 2020.
- Using MVLidarNet, it is possible to detect cars, bikes, etc., up to 200-300 objects in the scene with high accuracy and in real-time, while drawing 3D bounding boxes around each object, using only LIDAR data! The cars are represented by cuboids and pedestrians as cylinders. In addition to this, it is also possible to detect the green drivable space around the vehicle. This is shown in the image below:

- Here’s a short video by NVIDIA’s DRIVE lab describing how it works:https://www.youtube.com/embed/T7w-ZCVVUgM
- You can also find the original paper here.
- The image below shows the architecture of the pipeline:
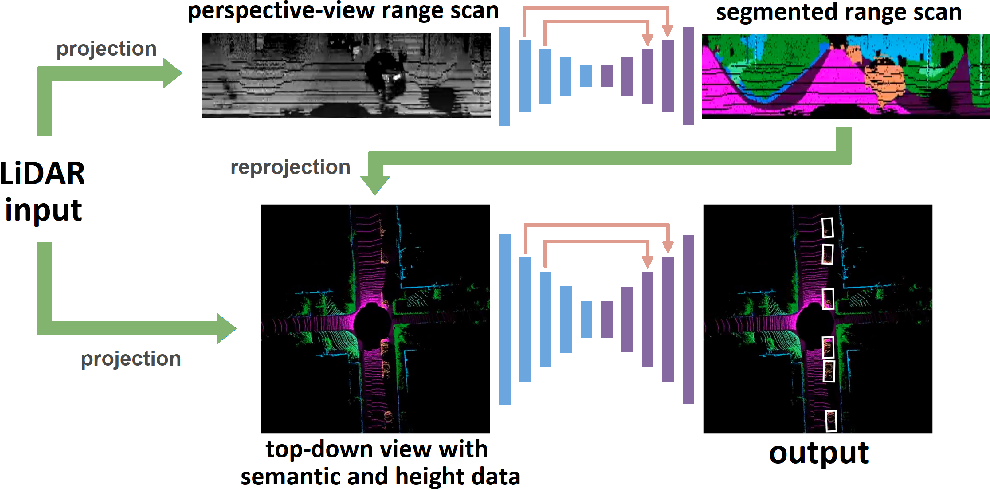
- MVLidarNet is actually a two deep neural network stack as a pipeline, one which looks at the perspective view and the other which looks at the top-down view.
- The first stage is responsible for detecting free-space and thus the drivable area for the self-driving car.
- The network is on-par with the state-of-the-art but is much faster in terms of implementation.Panoptic Segmentation
- While the above network works well for LIDARs, how can obtain the same rich contextual information for self-driving cars that are equipped with cameras?
- Here’s a quick video from NIVIDIA’s DRIVE lab that explains how they are using panoptic segmentation to provide the information with a camera. It detects cars, drivable space, and pedestrians. It’s impressive to see how the network is able to detect various instances (notice how each instance has a unique ID) of the classes amid occlusions, traffic cones, and traffic signs!https://www.youtube.com/embed/HS1wV9NMLr8
- This network is particularly useful in dense, unstructured and cluttered environments such as high traffic and dense pedestrian congregations, detecting up to 200-300 in a given frame.
- Here are the network architecture and a link to the blog in case you want to read more details.
- However, panoptic segmentation did not give us the depth of each object, i.e., how far each object is from the camera. For this, they employ a structure-from-motion neural network to compute the depth of various objects.
- Both networks are then combined in a similar multi-view perception CNN for cameras, similar to MVLIDAR.
Deep Neural Networks For Prediction And Planning
- This goal of CNNs for prediction and planning to take the perception output and use it to predict how entities will behave as well as plan motions around them.
- The DNN so formed is called PredictionNet, which is used to predict the future trajectories of road users based on live perception data from a bird’s eye view (from the MVLidarNet perception stack) and map data.
- The DNN looks into the past to analyze prior road user positions, while also taking into consideration positions of fixed objects, road signs, lane markings, and other landmarks. Here’s a quick video explaining this in detail:
- Usually, when this is implemented in the car, a combination of both LIDAR and camera is used for planning in run-time.
- This network also predicts the probability of a vehicle about to perform lane changes or the likelihood of turning left or right. Naturally, the researchers showed that it is possible to simulate several traffic scenarios and predict traffic at a time in the future.
- This traffic simulation provides a model of the world, and as a result, it is possible to use model-based reinforcement learning.
Active Cruise Control (ACC) For Model-Based RL Policy
- An active cruise control policy is trained from the output of the Prediction Net as a DNN for the control module of the navigation stack.
- Let us consider a hypothetical case of three cars in two lanes as shown in the image below.

- The car in red is conditioned with an RL policy and its job is to follow the blue car. We can condition the goal of the policy to prevent the green car from changing lanes and cutting in front of the red car.
- The researchers showed that using their model-based RL policy computed various varying accelerations for the red car over time, making it improbable for the green car to change lanes and cut into its path.
- In this manner, it is possible to incorporate DL into the control module of a self-driving car as well.
Summary
- This post talked about the typical structure of an autonomous vehicle stack and the level of DL being applied at each stage.
- Using MVLidarNet/Panoptic segmentation we can incorporate DL in the perception stage.
- Using PredictionNet, we can use DL in the prediction stage of the network.
- Finally, the control aspect can also be incorporated with DL using a model-based Active Cruise Control (ACC) Reinforcement Learning (RL) policy.
- Using a modular DNN based approach as proposed in this talk, it might be possible to better capture the various complexities of the world.
- Certain rare cases, such as crashes are usually not present in the data being used to train DNNs. In such cases, we can add safety parameters at the output of each module to check for safety considerations. Additionally, we can synthetically generate crash data and feed it into the learning stage of the DNNs.
- In conclusion, it is possible to build the entire self-driving car stack with DNNs, train each module individually, and fine-tune it to our requirements.
FAQ:
- What is a LIDAR?
- LIDAR stands for Light Detection and Ranging is a device that uses light in the form of pulsed lasers to measure variable distances. The differences in laser return times and wavelengths can be used to make digital 3D representations of the target. It finds several applications in terrestrial and aerial robotics systems. Have you seen Robot vacuum cleaners that automatically clean your house with an inbuilt map it constructs? Those robots use LIDARs. In fact, there a spooky hacking threat we need to be aware of when using devices equipped with LIDARs. It appears that hackers today are able to detect minute changes in vibrations around a sound source through a LIDAR and reconstruct the sounds. This is called a LIDARPHONE, and researchers were able to decipher audio with a 91% accuracy. Check out this paper to learn more. Here’s a video summarizing this, and the paper describing this in detail. https://www.youtube.com/embed/4Vf5_gYsNOk
- What is panoptic segmentation?
- Panoptic segmentation unifies the two distinct tasks of semantic segmentation( the process of assigning a class label to each pixel), while also doing instance segmentation (detect and segment each object instance). Trouble understanding this? Read this article to learn more.
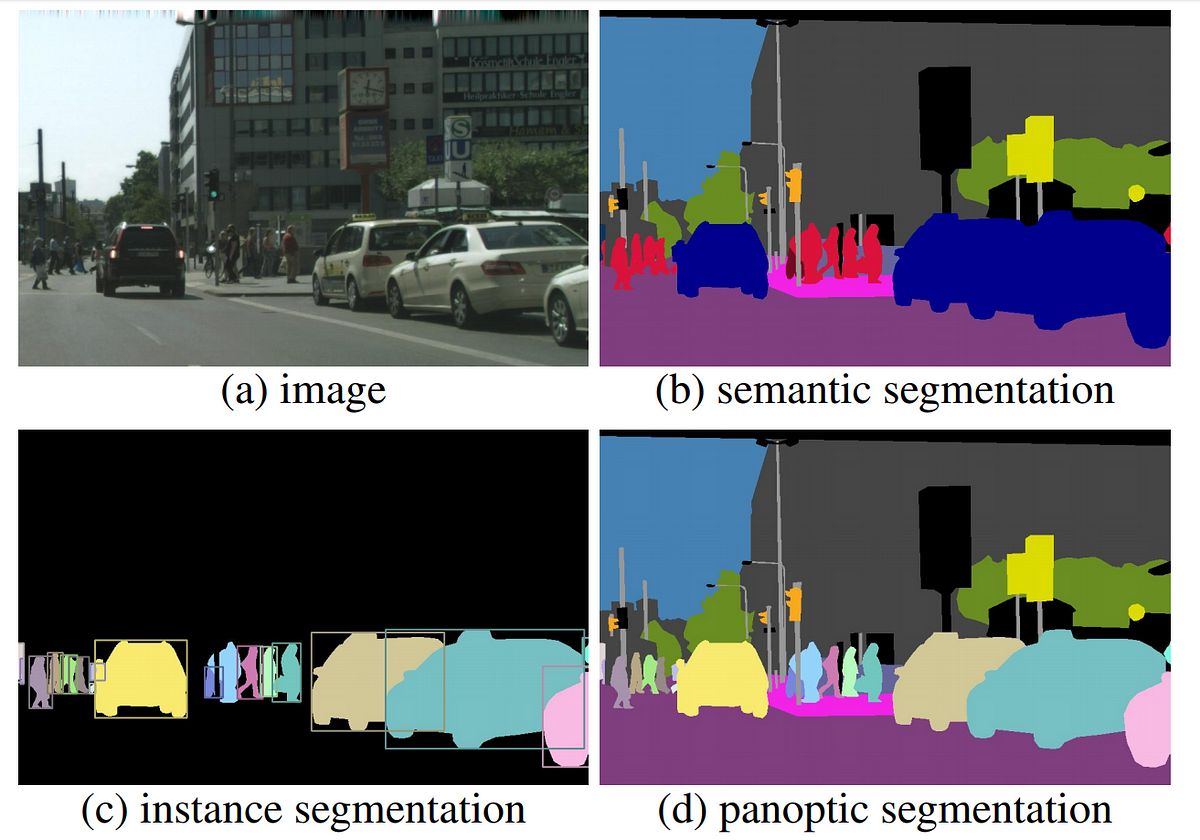 Image Source
Image Source
- Panoptic segmentation unifies the two distinct tasks of semantic segmentation( the process of assigning a class label to each pixel), while also doing instance segmentation (detect and segment each object instance). Trouble understanding this? Read this article to learn more.
Image Credits: The images used in this post have been adopted from the presentation or other external sources unless mentioned otherwise.