Introduction
It is often taken for granted how good humans are at operating under chaos. We bring order from disorder, and the most common example is how we are able to abstract useful information from messy and cluttered environments. This is ability however has made many humans lazy, and we hardly ever keep our environments organized. This is bad news for robots since reasoning about chaos and uncertainty is an extremely difficult skill for robots to attain.
My team and I took part in a competition called Open Cloud Robotics Table Organization Challenge (OCRTOC) held at IROS 2020. While we didn’t end up winning the competition, it was in this competition that I realized the profound difficulty of such a solution. Every seemingly obvious set of sets humans do to organize our world from clutter to order was a struggle for robot. It truly made me appreciate my own motor skills. For instance, the seemingly simple problem of grasping something can have such variability making it extremely hard to generalize for robots to perform with the same level of repeatability as humans.
Problem Statement
Now that I’ve set the preface, the formal introduction of the problem was as follows:
Let there be a set of rigid objects. A particular rearrangement task can be specified as X =
{O, C0, CT}, where O is the objects in the given task, C0 is the initial scene and CT is the given target scene. The initial scene C0 is not provided as input and has to be observed using visual sensors where each object’s pose has to be inferred from the scene. We provide the input CT and as a ROS world file to the system.

Approach
Our overall approach is summarized in the flowchart below:
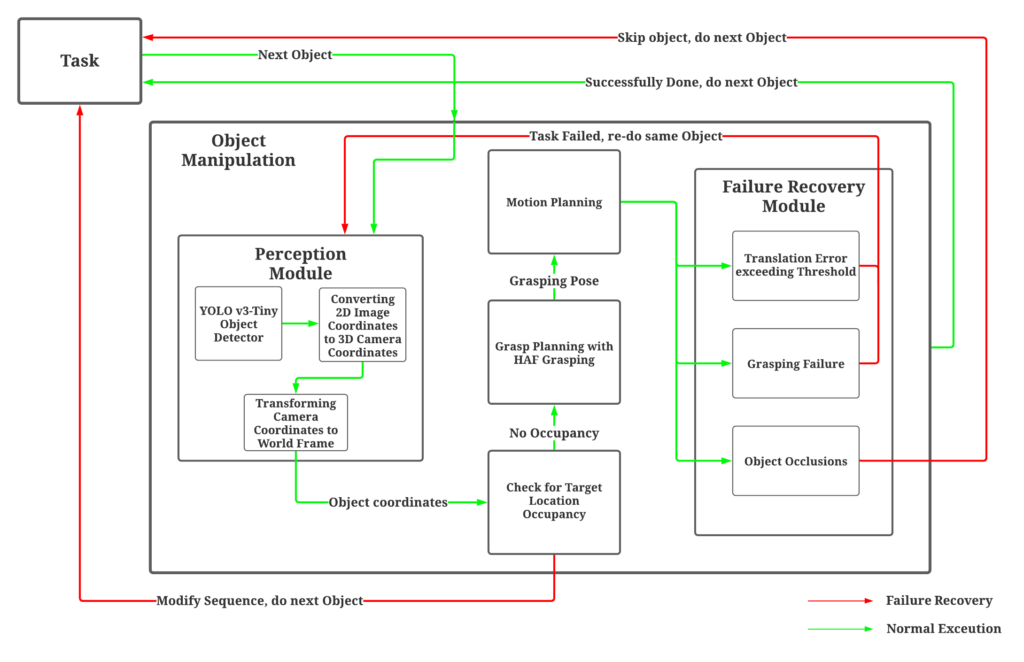
Our approach combines the components of robot vision, planning, control, and manipulation into a lightweight, flexible and integrated pipeline. The real-world system consists of a YASKAWA MotoMini manipulator with a parallel jaw gripper, a wrist-mounted Intel RealSense d435i depth camera, and an overhead Kinect camera. An identical setup is depicted in the simulation with a UR5 manipulator instead. The setup consists of a range of objects taken from the standard YCB dataset and cluttered into random configurations on a table workspace.
The components of the system are as follows:
- Perception : The perception components are based on YOLO v3-Tiny trained on a dataset containing 10 classes of objects, with approximately 400 images per class, consisting of only synthetic images taken from the simulation environment. To ensure simulation-to-real transfer, care was taken to ensure that the simulation environment resembles the real-world as much as possible, such as background features and lighting conditions. It is to be noted that although the simulated environment was close to the real world setup, the images collected were strictly non-photorealistic. The collected data was then augmented to increase the dataset size and prevent over-fitting of the model. Through transfer learning , the model is fine-tuned using the pre-trained weights of COCO and a custom dataset. The detected object’s geometric center is extracted using a Kinect sensor, and the corresponding 3D coordinates are later transformed to the world frame to get the absolute location of each object.
- Grasp pose Detection: After localizing the objects of interest, the arm hovers above the object such that the wrist-mounted camera is facing the table. The point cloud obtained from the camera is segmented using, and outliers are extracted to remove points corresponding to the face of the table. Height Accumulated Features (HAF) grasping framework is used for determining the optimal grasp pose candidate. It detects feasible grasps by analyzing the topographic features of the objects using support vector machines, which allow for the development of a relatively lightweight grasping framework.
- Planning and Control: An off-the-shelf TRRT motion planner is used with feasible inverse kinematic solutions being generated by OpenRAVE’s IKFast Plugin. ROS Control framework was used to provide the controllers and hardware interface for executing the motion plans computed.
Outcomes
The main outcomes of this project were as follows:
1) A lightweight, GPU-independent integration of subsystems that combines object detection, grasping, and motion planning into a flexible and robust table organization pipeline. In particular, our pipeline could sort objects in a cluttered environment involving three or more small to medium-sized graspable objects in close-proximity or overlapping each other. This is accomplished by employing a rigorous object detection scheme that searches for feasible grasps in a targeted and localized area in the object workspace, which is then seamlessly used to achieve precise targeted grasping. Moreover, the pipeline can rearrange the sorting order when one object has been occluded by other objects in the scene.
2) A robust failure tolerance system for handling common failure modes. From our experiments, the failure modalities primarily involved the object slipping out of the gripper or not being grasped at all, the target placing location being occupied by another object, and the final positioning of the objects at their target being inaccurate.
3) The pipeline is also platform-agnostic which we could demonstrate by making the system repeatable in simulation and real-world setups at varying scale. A transfer learning approach accomplished seamless simulation-to-real-world performance transfer using non-photorealistic training data for the object detection pipeline.
Overall, this project was a great introduction into the various problems that are yet to be solved in Robot autonomy. A major takeaway for me was the experience gained in system integration, building and organizing a complex software stack. There are several improvements that can be done to this pipeline which I hope to implement in the near future.